
| Version 3 (modified by manualwiki, 14 years ago) (diff) |
|---|
Module and Function Dependencies
Concerning terminology
We say that a module A is dependent on another module B (A -> B) if there is
at least one function call from A to B.
A cyclic dependency appears, when B is
also dependent directly (B -> A) or indirectly (e.g. B -> C -> A) from A.
Note that it is possible to have a cyclic dependency among the modules while having
no cyclic dependencies among the functions.
For example, a function call from
A:foo to B:foo, and from B:foo2 to A:foo2 implies a cyclic dependency on the
module level.
If one wants to have a deeper analysis and pays more
attention to the concerning functions, a function level query should be done.
In
our previous example, no function level cycle appears, unless A:foo calls B:foo,
and B:foo calls A:foo.
Possible Analysis
The following examinations can be done considering dependencies:
- Checking whether there are cycles, if so, listing them out
- Printing out the cycles, meaning the modules/functions will not be represented by their proper graph node, but with their names (instead {'$gn', module, 3} there will be test).
- Checking for cycle from one or more nodes as starting points
- Drawing the dependency graph
- Drawing the dependency graph from a starting node
- Drawing the cyclic part of the dependency graph if one exists (you can also give a cyclic node as a starting node)
Dependency analysis can be done through two interfaces:
- ri (using RefactorErl? through console interface)
- using the web interface.
The two interface functions are:
- ri:draw_dep/1 - for drawing
- ri:print_dep/1 - for listing, printing out to the standard output
To call the desired query, the user should give a proplist, stating the different requirements.
The options and the keys for the functions are:
- {level, Level}
Level = mod | func
Stating the level of the query, module or function level.
- {type, Type}
Type = all | cycles
The investigation should be done on the whole graph/table, or just on the cycle part (if it exists).
When listing out the cycles, all gives back the result in their graph node form, while cycles returns with their proper names.
Examples for listing results
- Checking for cycles in module level.
ri:print_dep([{level, mod}, {type, all}]).
- Checking for cycles in function level, and printing out the whole names of the functions (Module:Function/Arity).
ri:print_dep([{level, func}, {type, cycles}]).
{6 cycle(s),
[['foo:fv4/1','foo:fv4/1'],
['test3:p/1','test:fv6/1','test3:p/1'],
['cycle4:f4/1','cycle3:f3/1','cycle4:f4/1'],
['cycle2:fv2/1','cycle1:fv1/0','cycle2:fv2/1'],
['test:fv5/1','test:fv4/2','test:fv5/1'],
['cycle4:f5/1','cycle3:f6/1','cycle4:f5/1']]
- Checking for cycles in function level, and printing out the graph nodes of the functions (notice the changed "type" in the proplist)
ri:print_dep([{level, func}, {type, all}]).
{"6 cycle(s)",
[[{'$gn',func,28},{'$gn',func,28}],
[{'$gn',func,29},{'$gn',func,37},{'$gn',func,29}],
[{'$gn',func,7},{'$gn',func,9},{'$gn',func,7}],
[{'$gn',func,2},{'$gn',func,1},{'$gn',func,2}],
[{'$gn',func,36},{'$gn',func,35},{'$gn',func,36}],
[{'$gn',func,8},{'$gn',func,6},{'$gn',func,8}]]}
- Checking for cycles in module level from an exact node
ri:print_dep([{level, mod}, {gnode, {'$gn', module, 24}}]).
{true,[[{'$gn',module,24},
{'$gn',module,25},
{'$gn',module,24}]]}
- Checking for cycles in function level from an exact node given with its whole name
ri:print_dep([{level, func}, {gnode, "cycle4:f5/1"}]).
Representation
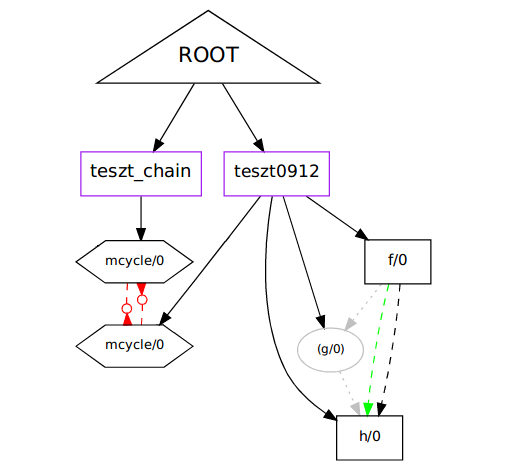
Function Level
Let's take an example to explain the meaning of the representation of
dependency graphs. A ri:draw_dep([{level, func}, {type, all}])
call was made, which generated a Graphviz dot file.
!!TODO: add figure!!
Explanation of the figure:
- ROOT triangle - no actual purpose, functioning as a starting point, only appears in the representation
- Rectangle/box nodes (eg.: cycle1, a, test2) - representing modules (colour: deep purple)
- Hexagon nodes (eg.: f1/1, apply/3, test2/2) - representing functions (colour: black)
- Double octagon nodes - representing opaque nodes (colour: black, label colour: gray)
- Solid, continuous edge, normal arrowhead - normal edge indicating the modules from the root, and the
modules and their definitions of functions (colour: black)
- Dashed edge, normal arrowhead - indicates that a function calls another function (funcall) (colour: black)
- Dashed edge, special arrowhead - indicated a function call, but also that it is a cyclic edge (colour: red)
The next figure was made after a ri:anal_dyn() was run, which is a dynamic analyser. Due to its work the call graph changes a bit, new types of nodes and edges are introduced.
!!TODO: add figure!!
Explanation of figure, new nodes, edges:
- Double octagon nodes - representing opaque, -1 arity nodes (colour: black, label colour: gray)
- Dotted edge, normal arrowhead - indicates an ambcall, dyncall, may_be edge (colour: black)
Every node and edge have tooltips. In the case of nodes it shows the adequate graph node, while considering edges it depicts the type of function call (funcall, may_be, ambcall, dyncall). Static calls are labelled by funcall.
Dyncall means unambiguous dynamic calls, when the identifiers of the callee may be defined not at the call but at another program part, and their values are can be calculated by data-flow reaching. Ambcall relation denotes the fact that some of the arguments of the dynamic function call can not be detected statically. If the number of parameters is uncertain, then after the arity of the function will be -1. It is also indicated with a special node. For further details about the dynamic calls and their representation can be found in (TODO: Reference for dynamic calls). When the applied function or module is uncertain, the tool represents it with an opaque node, and connects the possible functions/modules with may_be edges. The representation in the analysis now follows this, indicating the opaque nodes differently (described in the previous section, concerning drawings).
We note here that tooltips may not be shown under certain browsers (for example Mozilla Firefox 7.0.1). If this happens, please try another browser.
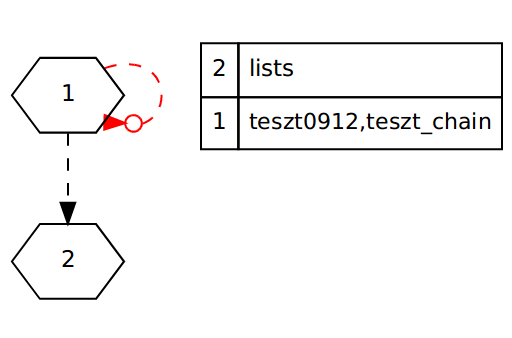
Module Level
Similarly, at module level, after calling {{{ri:draw_dep([{level, mod}, {type, all}])}}, an analogous figure can be achieved.
!! TODO Figure !!
Explanation of figure:
- Rectangle/box nodes (eg.: cycle1, erlang, test2) - representing modules (colour: deep purple)
- Doubleoctagon nodes (no example on the figure) - representing opaque nodes (colour: black, label colour: gray)
- Dotted edge, normal arrowhead - indicates that a module calls another module (colour: black)
- Dotted edge, special arrowhead - indicated a module call, but also that it is a cyclic edge (colour: red)
The tooltip for edges shows a list the function pair:
Call = {callee, called}, Tooltip = [] | [Call | Tooltip]
Latter makes a connection between the modules with this call.
Examples for the representation of the results
- ri:draw_dep([{level, mod}, {gnode, erlang}]).
- ri:draw_dep([{level, mod}, {gnode, erlang}, {dot, "/home/working/dot/test.dot" }]).
- ri:draw_dep([{level, func}, {gnode, "lists:hd/1"}]).
- ri:draw_dep([{level, mod},{gnode, {'$gn', module, 4}}]).
- ri:draw_dep([{type, cycles}, {level, func}, {gnode, {'$gn', func, 36}}]).
Function block dependencies
About function blocks
In large systems, sets of applications (which themselves consist of several modules) are organised into bigger units; keeping in line with
Ericsson terminology, we shall call these function blocks. We also seek dependencies between them, which is conceptually similar to
dependencies between modules: a function block FB1 is dependent on a function block FB2 if a module from FB1 is dependent on one from FB2.
In the following, we shall presume that all function blocks reside in directory trees, and that all modules contained in the tree are loaded
into the database.
If we want to sum up what function blocks are, it should be said that they are groups of modules, in which every function block on its own
attains a certain functionality. However, there can be several concepts how exact function blocks can be distinguished. Three ways will be presented.
- Considering every directory as a function block is not a far to seek option. The exact absolute paths of every module manages them into unambiguous units, and between these units module relationships give the basis of the dependency analysis.
- Continuing the absolute path logic, one may come to the point when these absolute paths need to be generalised, or following some kind of structure or concept. The tool provides interface for this request as well, since it is possible to define function blocks by the means of regular expressions. In this way, for example every module in the .*/src/ directories can be considered as one block, and connections outside of this function block (for instance, relationship investigation with .*/ebin/ directories) can be determined. The default definition of function blocks comes from the NetSim? team which is defined as a regular expression. The default rule can be overridden by redefining the regular expression (exact regexp is given in the TODO reference to Defining function blocks with regular expressions paragraph).
- To define a function block is to list its contents. The user can define his own function blocks in 3 ways, with defining the exact modules (eg.: module1, module2, module3, placed in three different directories, can a function block), giving the absolute directory path with/without regular expressions (to give it further thought, the exact absolute path is also a regular expression) and giving structure of the names and absolute paths of Erlang source files with regular expressions (example in TODO refernce User defined function blocks} paragraph).
Using function block analysis in ri
The function ri:fb_relations/1 is used for the function block dependency analysis. The argument, which is again a proplist of this function determines the exact examination type.
The Options are the following:
- {command, Command}
Command = get_rel | is_rel | check_cycle | draw | draw_cycle- get_rel Displays the relationship between the given function block list. The result is a tuplelist where a tuple represents a relation.
- is_rel Decides whether there is a connection between the two given function blocks.
- check_cycle Checks for cycles in the dependencies between the given function block list. Unless list is given, checks among every function block list.
- draw Prints out the entire graph or creates a subgraph drawing from the given function block list. Output file is fb_relations.dot.
- draw_cycle Prints out a subgraph which contains the cycle(s). Unless cycles exist, prints out the entire graph. Output file is fb_rel_cycles.dot.
- {fb_list, List}, List = [string()] | [{Basename::string(), [Function block::atom()]}]
Chosen function block lists for further examinations. If no list given, then it takes every function block list, which means that every absolute path defines a function block.
- {other, Other} Other = bool()
The Other parameter stands whether the category "Other" would be taken into consideration or not (true/false). The default value is true.
Examples
- ri:fb_relations([{command, check_cycle}]).
- ri:fb_relations([{command, draw_cycle}]).
- ri:fb_relations([{command, is_rel}, {fb_list,["path_to_dir/subdir", "path_to_dir/subdir/subsubdir"]}]).
- ri:fb_relations([{command, is_rel}, {fb_list,{"path_to_dir", [1, 2]}}]).
Optional Other category
Let's think about function blocks in the sense that every directory with its absolute path gives a different function block. The Other category is a special collector name for those modules which cannot be divided into any function block. Practically this covers those modules which do not have directories (for example, usually erlang). This category can be taken into consideration as a false function block, so a new option was introduced for eliminating this category. With this the dependencies with Other category are skipped, the tool takes into consideration only the real connections.
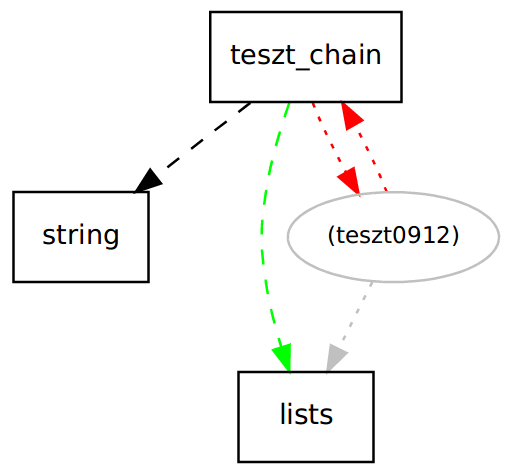
Representation of Function block Dependency Graphs
Naturally, it is possible to represent function block relationships with the previously used dot files. Using the command key in the Options proplist, the desired figure can be gained (draw or draw_cycle). It could be useful to make the standard output messages also available, because function blocks are represented with numbers. However, as a tooltip the proper function block name is provided.
>> ri:fb_relations([{command, draw}]).
Earlier results deleted (except .dot files).
Building dependency table...
Creating "/home/RefactorErl/tools/new/tool/dep_files/fb_relations.dot" file...
Function block 1 is "/home/RefactorErl/test/cyclic/cycles"
Function block 2 is "/home/RefactorErl/test/regexp/common/serv1/ebin"
Function block 3 is "Other"
Function block 4 is "/home/RefactorErl/test/error"
Function block 5 is "/home/RefactorErl/test/cyclic/no_cycle"
Function block 6 is "/home/RefactorErl/test/opaque"
Function block 7 is "/home/RefactorErl/test/regexp/common/serv2/lib/ebin"
!!! TODO add figure !!!
Explanation of figure:
- Hexagon nodes (eg.: cycle1, erlang, test2) - representing function blocks as number (colour: black)
- Dotted edge, normal arrowhead - indicates that a fb calls another fb (colour: black)
- Dotted edge, special arrowhead - cyclic edge (colour: red)
Using function block analysis from the web interface
The usage of function block analysis is described in !!! TODO add ref.!!!
Defining function blocks with regular expressions
Function blocks can be filtered by the means of regular expressions. An interface function, called {{{ri:fb_regexp/1}} is provided and its parameters are the following:
- {type, Type}
Type = list | get_rel | cycle | draw- list Prints out every function block which matches the basic regular expression.
- get_rel Decides whether there is a connection between the two given function blocks.
- cycle Checks for cycles in the dependencies between the given function block list.
- draw Prints out the entire graph or creates a subgraph drawing from the given function block list. Output file is fb_relations.dot or can be user defined with the dot key.
- {regexp, Value}
Value = File::string() | [RegExp::string()]
If this option (tuple) is not given, the program works with a basic regular expression. The basic rule: <function block>/common/<service>/ebin or <function block>/common/<service>/lib/ebin.
The regular expression saved for this: (/)[0-9a-zA-Z_./]+/common/[0-9a-zA-Z_.]+/(lib/)?(ebin)$
- Value - If the regular expression is given in a file then every single regexp has to be defined in a separate line and must follow the Perl syntax and semantics as the http://www.erlang.org/doc/man/re.html erlang module resembles so. However, the user can give the regular expressions in a list as well. If there is an error with a regular expression in the file or in the list, it prints out the regexp, the error specification, and the position. The most usual regexp is ".*" (the Perl syntax does not allow simply "*", because this symbols means possible unlimited repetition of characters declared before it, and there are no characters declared before it)
Examples:
- ri:fb_regexp([{type, draw}, {dot, test.dot}]).
- ri:fb_regexp([{type, list}, {regexp, "regexp"}]).
- ri:fb_regexp([{type, list}, {regexp, "^/home/[a-z./]+}]).
User defined function blocks
One can make his own function block in the following three ways:
- Giving the exact modules (with their name) which should be in one function block.
- Regular expressions covering the structure of the directories.
- By regular expressions covering the structure of the directories and the structure of the name of the files.
Example: refusr_fb_regexp:re([{type, list}, {fb, [[cycle1, cycle2],"/home/user/[a-zA-z]*", "/home/user/[a-zA-z./]*/.*_ui.erl"]}]).
Optimisations
For efficiency and time improving reasons, the result of the queries are saved into dets tables for the further queries.
The results of previous queries are saved into dets tables (in the dep_files directory). This means that if the same query is run, the execution time may decreases significantly. At first run, a digraph is built as in the previous version, only it is saved later.If there was a whole database dependency check, than the tool works from that dets table instead of building a new subgraph, which also improves time efficiency. Due to this, it is strongly advised that if one knows that a lot of different node queries will be done, a whole check should be run in the first place. The saves are available until the database is unchanged. At the moment the hash value of the database is changed, the existing dets tables are deleted. The deletion does not effect the .dot files, although it is significant to remember to save them somewhere else from the dep_files directory, because the next call for draw function will overwrite the corresponding .dot file. This could be prevented by using the feature, that the user can define his own dot file name and absolute path.
Attachments (3)
- function_graph.png (28.0 KB) - added by tothm 11 years ago.
- mb_graph.png (12.6 KB) - added by tothm 11 years ago.
- module_graph.png (20.7 KB) - added by tothm 11 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip